
Convolution Operation:
• Convolution operation makes the specialty of extracting or keeping the critical functions from the entries. Convolution operation permits to community to discover horizontal and vertical edges of an picture after which primarily based on those edges build excessive-stage features inside the following layers of neural network. In general shape, convolution is an operation on functions of a real valued argument. To inspire the definition of convolution, we start with examples of two capabilities we would use.
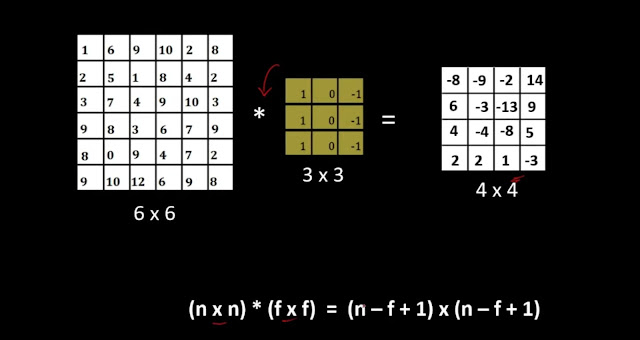
• Convolution operation makes use of 3 parameters: Input photograph, Feature detector and Feature mup.
• Input photo is transformed into binary I and 0. It is regularly interpreted as a filter out wherein the kernel filters enter statistics for sure sorts of statistics.
• Sometimes a five x 5 or a 7x7 matrix is used as a function detector. The function detector is frequently known as a "kernel" or a "filter out,". At each step, the kernel is accelerated by way of the enter facts inside its bounds, creating a single access within the output function map.
Components of convolutional layers are as follows:
a) Filters
b) Activation maps
c) Parameter sharing
d) Layer-unique hyper-parameters
• Filters are a feature that has a width and height smaller than the width and height of the input quantity. The filters are tensors and they may be used to convolve the input tensor when the tensor is handed to the layer example. The random values within the clear out tensors are the weights of the convolutional layer.
• Sliding every filter out throughout the spatial dimensions (width, height) of the enter extent throughout the forward skip of statistics through the CNN. This produces a two dimensional output referred to as an activation map for that unique filter.
Parameter Sharing:
• Parameter sharing is utilized in CNN to govern the whole parameter rely. Convolutional layers reduce the parameter be counted further by using using a technique known as parameter sharing. • The consumer can reduce the range of parameters by making an assumption that if one feature can compute at a few spatial role (x), then it's miles beneficial to compute a extraordinary region (K)
• In other phrases, denoting a unmarried 2D slice of intensity as a depth slice. For instance, for the duration of again-propagation, every neuron in the community will compute the gradient for its weights however these gradients could be added up throughout every depth slice and most effective replace a single set of weights in keeping with slice
• If all neurons in a unmarried depth slice are using the equal weight vector, then the forward skip of the convolutional layer can be computed in each intensity slice as a convolution of the neuron's weights with the input volume. This is the motive why it's miles not unusual to refer to the sets of weights as a filter out (or a kernel), this is convolved with the enter.
Equivariant Representation:
• Convolution function is equivariant to translation. This means that shifting the input and making use of convolution is equal to applying convolution to the enter and shifting it If we move the object in the input, its representation will pass the same quantity within the output
• General definition: If representation(remodel(x)) = transform(illustration then illustration is equivariant to the remodel.
• Convolution is equivariant to translation. This is an instantaneous outcome of parameter sharing. His useful whilst detecting systems which can be commonplace inside the enter. For example, edges are Equivariance in early layers is ideal. We are able to achieve translation-invariance (through max-pooling) because of this property.
• Convolution isn't always equivariant to different operations consisting of exchange in scale or rotation.
Example of equivariance: With 2D photos convolution creates a map wherein sure capabilities appear in the input. If we pass the object in the enter, the representation will circulate the identical quantity within the output. It is beneficial to locate edges in first layer of comvolutional community. Same edges seem anywhere in picture so it's miles realistic to proportion parameters across entire picture).
Padding:
• Padding is the procedure of adding one or greater pixels of zeros all over the limitations of an photo, if you want to increase its effective length. Zero padding helps to make output dimensions and kemel size independent.
• One remark is that the convolution operation reduces the size of the (q 1) ^ m layer in contrast with the dimensions of epsilon * q ^ 3 layer. This type of discount in length isn't acceptable in wellknown, because it has a tendency to lose a few information along the borders of the image. This trouble can be resolved by the usage of padding.
• 3 common zero padding strategies are:
a) Valid convolution : Extreme case wherein no 0-padding is used in any respect, and the convolution kemel is handiest allowed to visit positions wherein the complete kernel is contained totally inside the enter. For a kernel of length ok in any size, the enter form of m in the course turns into m - k i inside the output. This shrinkage restricts architecture depth.
b) Same convolution: Just enough zero-padding is added to preserve the scale of the output same to the scale of the input. Essentially, for a dimension wherein kernel length is k, the enter is padded by means of okay = 1 zeros in that dimension.
c) Full convolution: Other intense case where enough zeroes are added for each pixel to be visited ok times in cach course, ensuing an output photograph of width m okay - 1 d) The ID block is composed by means of a configurable variety of filters, in which the filter has a fixed size, a convolution operation is executed among the vector and the clear out, producing as output a new vector with many channels because the variety of filters.
Every value inside the tensor is then fed through an activation characteristic to introduce nonlinearity When padding isn't used, the resulting "padding" is likewise known as a legitimate padding Valid commonly does not paintings nicely from an experimental point of view. In the case of legitimate padding, the contributions of the pixels at the borders of the layer could be compared to the central pixels inside the next hidden layer, which is unwanted.
Stride:
• Convolution capabilities used in exercise range slightly as compared to convolution operation As additionally it is understood inside the mathematical literature. In standard a convolution layer includes application of numerous different kernels to the input is usually not real-valued but as an alternative vector valued. Multi-channel convolutions are commutative most effective if number of output and enter channels is the equal. In order to permit for calculation of functions at a coarser degree strided convolutions can be used. The impact of strided convolution is the same as that of a convolution followed through a down sampling degree. This may be used to reduce the representation size.
• The stride shows the tempo with the aid of which the filter movements horizontally and vertically over the pixels of the input photo at some stage in convolution. Stride for the duration of convolution.
• Stride is a parameter of the neural community's clear out that modifies the quantity of movement over the picture or video. Stride is a for the compression of images and video statistics. For example, if a neural community's stride is set to one, the clear out will flow one pixel or unit, at a time. If stride= 1, the clear out will move one pixel. • Stride depends on what we count on in our output picture. We prefer a smaller stride size if expect numerous nice-grained capabilities to mirror in our output. On the opposite hand, if we are best inquisitive about the macro-degree of capabilities, we pick a larger stride length.
Post a Comment